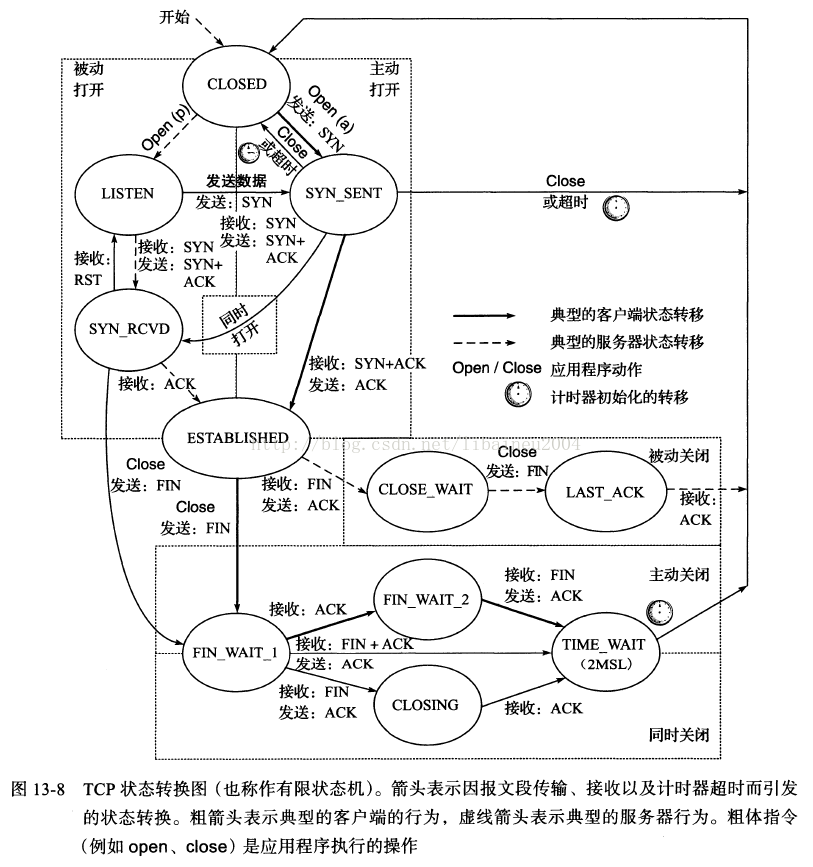
TCP状态迁移图


FIN 段是可以携带数据的,比如客户端可以在它发送的最后一块数据块中“捎带” FIN 段。当然也可以单独发送FIN。不管 FIN 段是否携带数据,都需要消耗一个序列号。
TCP三次握手的缺陷:Sync Flood攻击
确认机制与超时重传
TCP通过确认机制 ( acknowledge ) 保证了信息的成功发送。
发送的数据编号被称为序列号(Sequence Number - SN)
确认的数据编号被称为确认序列号(Ackonwledge Sequence Number - ASN)
TCP协议正是通过序列号保证了传输顺序
ASN = 填写要接收的下一个字节的数据(本次收到的数据的最后一个字节的下一个)
TCP是有发送缓冲区的,用于暂时保存已发送,未应答的数据,为什么要进行保存,因为TCP为了保证数据确切地被对方接收到,需要对方发送的ASN,如果对方没有应答,就需要重发,如果不对数据进行保存,就没有办法重发了,所以发送缓冲区主要也是为了保证可靠性而存在的
TCP有接收缓冲区,这与UDP协议一致,因为接收到的信息,不一定马上就能被应用层取走使用
TCP规定,SYN报文段不能携带数据,但要消耗一个序号;ACK报文段可以携带数据,但如果不携带数据则不消耗序号
客户端在收到第三次挥手的FIN 报文之后,再次收到服务端的数据包会怎么处理
客户端如果收到乱序的 FIN 报文,会将FIN包加入到「乱序队列」,并不会进入到 TIME_WAIT 状态。等收到前面被网络延迟的数据包时,重组报文得到完整顺序的数据包之后,发现有 FIN 标志,这时才会进入 TIME_WAIT 状态。
关于TIME_WAIT存在的必要性
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
1)为实现TCP全双工连接的可靠释放
由TCP状态变迁图可知,假设发起主动关闭的一方(client)最后发送的ACK在网络中丢失,由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发其FIN,在该FIN到达client之前,client必须维护这条连接状态,也就说这条TCP连接所对应的资源(client方的local_ip,local_port)不能被立即释放或重新分配,直到另一方重发的FIN达到之后,client重发ACK后,经过2MSL时间周期没有再收到另一方的FIN之后,该TCP连接才能恢复初始的CLOSED状态。如果主动关闭一方不维护这样一个TIME_WAIT状态,那么当被动关闭一方重发的FIN到达时,主动关闭一方的TCP传输层会用RST包响应对方,这会被对方认为是有错误发生,然而这事实上只是正常的关闭连接过程,并非异常。
2)为使旧的数据包在网络因过期而消失;防止lost duplicate对后续新建正常链接的传输造成破坏。
lost duplicate在实际的网络中非常常见,经常是由于路由器产生故障,路径无法收敛,导致一个packet在路由器A,B,C之间做类似死循环的跳转。IP头部有个TTL,限制了一个包在网络中的最大跳数,因此这个包有两种命运,要么最后TTL变为0,在网络中消失;要么TTL在变为0之前路由器路径收敛,它凭借剩余的TTL跳数终于到达目的地。但非常可惜的是TCP通过超时重传机制在早些时候发送了一个跟它一模一样的包,并先于它达到了目的地,因此它的命运也就注定被TCP协议栈抛弃。
另外一个概念叫做incarnation connection,指跟上次的socket pair一摸一样的新连接,叫做incarnation of previous connection。
lost duplicate加上incarnation connection,则会对我们的传输造成致命的错误。
大家都知道TCP是流式的,所有包到达的顺序是不一致的,依靠序列号由TCP协议栈做顺序的拼接;假设一个incarnation connection这时收到的seq=1000, 来了一个lost duplicate为seq=1000, len=1000, 则tcp认为这个lost duplicate合法,并存放入了receive buffer,导致传输出现错误。
通过一个2MSL TIME_WAIT状态,确保所有的lost duplicate都会消失掉,避免对新连接造成错误。
TCP拥塞控制
流量控制(狭义):根据对方的接收能力来调节发送流量
拥塞控制:根据网络的承载能力来调节发送流量
接收窗口大致 = 接收缓冲区大小 - 已用大小(接收的数据,暂时没被应用层读走)
发送窗口 = min(接收窗口, 拥塞窗口)
核心:拥塞窗口 cwnd
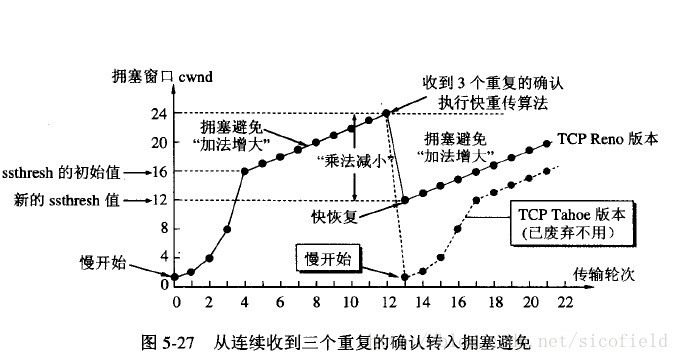
第一阶段:慢开始、拥塞避免
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
第二阶段;快重传、快恢复
快重传配合使用的还有快恢复算法,有以下两个要点:
①当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
②考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。