round-robin
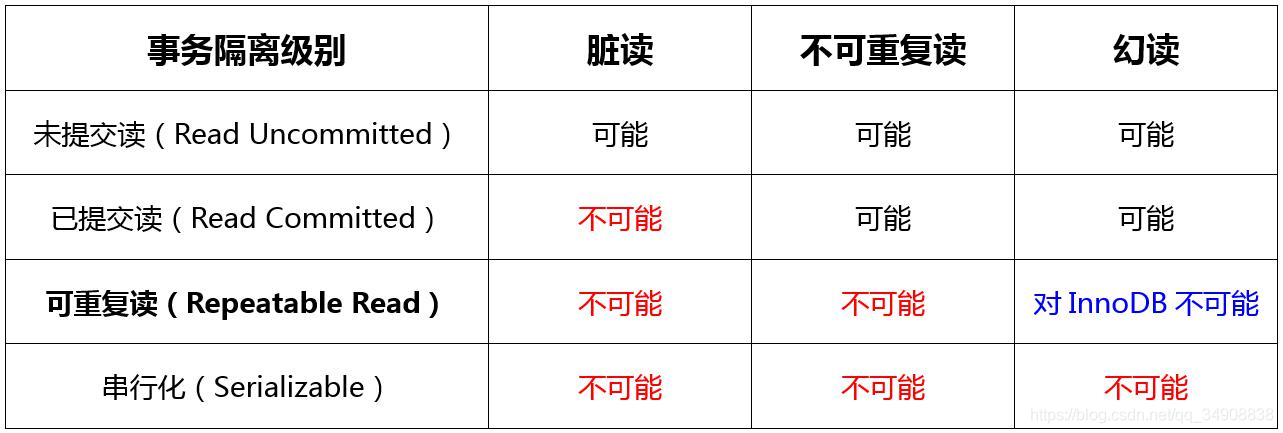
总是选择列表中的下一台服务器,结尾的下一台是开头,无需其他设置。比如有3台机器a,b,c,那么brpc会依次向a, b, c, a, b, c, …发送请求。注意这个算法的前提是服务器的配置,网络条件,负载都是类似的
Weighted Round Robin
根据服务器列表配置的权重值来选择服务器。服务器被选到的机会正比于其权重值,并且该算法能保证同一服务器被选到的结果较均衡的散开
不足:
- 无法快速摘除有问题的节点
- 无法均衡后端负载
- 无法降低总体延迟
nginx的WRR算法原理如下:
每个服务器都有两个权重变量:
a:weight,配置文件中指定的该服务器的权重,这个值是固定不变的;
b:current_weight,服务器目前的权重。一开始为0,之后会动态调整。
每次当请求到来,选取服务器时,会遍历数组中所有服务器。对于每个服务器,让它的current_weight增加它的weight;同时累加所有服务器的weight,并保存为total。
遍历完所有服务器之后,如果该服务器的current_weight是最大的,就选择这个服务器处理本次请求。最后把该服务器的current_weight减去total。
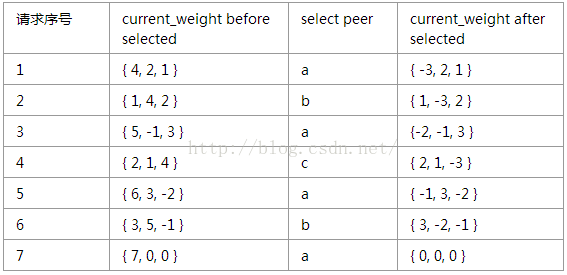
动态感知版的Weighted Round Robin
动态感知的WRR
peer.score = success_rate /(lantency * cpuUsage)
具体做法:
- 利用每次RPC请求返回的Response夹带CPU使用率
- 每隔一段时间整体调整一次节点的权重分数
不足:
自动刷新权重值,但是在刷新时无法做到完全的实时,再快也不可能超过一个 RTT,都会存在一些信息延迟差。当后台资源比较稀缺时,遇到网络抖动时,就可能会把该节点炸掉,但是在监控上面是感觉不到的,因为 CPU 已经被平均掉了。
best of two random choice
repsonse中附带cpu使用率,信息滞后造成了严重的羊群效应
计算权重分数,每次请求来时我们都会更新延迟,并且把之前获得的时间延迟进行权重的衰减,新获得的时间提高权重,这样就实现了滚动更新

时间衰减系数的滑动平均值:伴随时间,老的均值,权重越来越小,新的response time,越来越高
randomized
随机法,是随机选择一台服务器来分配任务。它保证了请求的分散性达到了均衡的目的。同时它是没有状态的不需要维持上次的选择状态和均衡因子。但是随着任务量的增大,它的效果趋向轮询后也会具有轮询算法的部分缺点。
根据随机算法,将请求随机分配到后端服务器中,请求的均匀请求依赖于随机算法,该实现方式较为简单,常常可以配合处理一些极端的请求,例如热点请求情况。不适合对命中率有要求的场景。
consistent-hashing
Hash哈希是根据Source IP、 Destination IP、URL、或者其它,算hash值或者md5,再采用取模,相同的请求会请求到同一个后端服务器中。该算法无法解决热点请求,会把某个时间段的热点请求路由到某个单机上,造成雪崩效应,同时在扩充和节点宕机时发生命中率急剧降低的问题(hash算法导致),该策略适合维护长连接和提高命中率。Consistanct Hash是对Hash 算法的优化,可以有效的解决宕机和扩充造成的命中率急剧降低的问题。
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0~2^32-1(即哈希值是一个32位无符号整形)。
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。
brpc locality-aware
优先选择延时低的下游,直到其延时高于其他机器,无需其他设置
在DP 2.0中我们使用了一种新的算法: Locality-aware load balancing,能根据下游节点的负载分配流量,还能快速规避失效的节点,在很大程度上,这种算法的延时也是全局最优的。基本原理非常简单:
以下游节点的吞吐除以延时作为分流权值。
比如只有两台下游节点,W代表权值,QPS代表吞吐,L代表延时,那么W1 = QPS1 / L1和W2 = QPS2 / L2分别是这两个节点的分流权值,分流时随机数落入的权值区间就是流量的目的地了。
一种分析方法如下:
稳定状态时的QPS显然和其分流权值W成正比,即W1 / W2 ≈ QPS1 / QPS2。
根据分流公式又有:W1 / W2 = QPS1 / QPS2 * (L2 / L1)。
故稳定状态时L1和L2应当是趋同的。当L1小于L2时,节点1会更获得相比其QPS1更大的W1,从而在未来获得更多的流量,直到其延时高于平均值或没有更多的流量。
具体见:
Locality-aware
任务:子任务
自然任务NatureTask,用户任务, TaskKey 用户邀请别人点赞达到10,自己去下单金额超过100(考虑逆向)
状态机(根据规则引擎的判定结果,决定状态机往哪边走)
变与不变,不变的部份,通过代码落地下来;变的部份,通过规则引擎来处理。
不变的部份:事件是可以枚举的,奖励是可以枚举的;
变的部份:任务参数会变,活动周期会变,累加规则会变,事件奖励的各种组合
写别样的代码…
PM运营沟通,让他们尽量少提没有通用性的需求;
熟悉业务的同时,给出自己的技术方案
给大家打鸡血,协同大家一起完成1.0版
救火案例2
B站微博系统,