数据库索引一些经常考察的知识点
mysql数据库索引
- Mysql 数据库有哪些索引以及他们各自的特点?InnoDB为什么选择用B+树作为索引,而不用B树?
| 索引 | 特点 | 使用场景 |
|---|---|---|
| hash索引 | 散列表实现,等值查询效率高,不能排序,不能进行范围查询 | 不需要范围查询,仅需等值查询时,可以考虑使用 |
| BTree索引 | B+树实现,支持范围查询 | 默认 |
| RTree索引 | 仅支持地理位置类型,RTree空间树实现,相比Btree有更好的范围查询性能 | 有按照地理位置检索需要的场景 |
| FullText索引 | 分词加倒排索引实现 | 有类似like的全文检索类型的查询 |
相比B树,B+树索引支持范围查找。
索引匹配原则:左前缀匹配原则
聚簇索引、非聚簇索引
| 索引 | 特点 | 使用场景 |
|---|---|---|
| 聚簇索引(clustered index) | 数据按照索引顺序存储,叶子节点存储真实的数据 | InnoDB索引 |
| 非聚簇索引(secondary index,non-clustered index) | 叶子节点存储指向真正数据行的指针 | MyISAM |

数据库回表
数据库回表是怎么回事?如何避免?
在查询辅助索引时,如果要查询的字段已经全部在索引中了,那么就不需要额外再查询主索引了;反之,如果要查询的字段当前索引无法覆盖,那么Mysql需要额外查询主索引去获取要查询的字段,访问索引的次数多了一次,我们称刚才的过程为回表。我们通过增加全覆盖索引可以避免回表。
InnoDB索引与MyISAM索引的区别
| 索引 | 特点 | 使用场景 |
|---|---|---|
| InnoDB索引 | InnoDB的主索引的叶子节点就是数据本身,而辅助索引的叶子节点是主键ID | InnoDB索引 |
| MyISAM索引 | InnoDB的主索引与辅助索引没有区别,叶子节点存储都是指向真实数据行的指针 | MyISAM |
索引为什么要用B+树来实现?
首先,相比红黑树、AVL等二叉平衡树,B+树更加矮胖,这样子索引查找便能够更好的访问磁盘IO,从而有更好的查询性能;另外相比B树,B+树在叶子节点之间维护了一根链表,借助该链表,范围查找性能更加稳定。两种存储引擎区别与各自使用场景

| 存储引擎 | 特点 | 使用场景 |
|---|---|---|
| MyISAM | 不支持外键,表锁,插入数据时锁定整个表,查表的总行数不需要扫表,索引与数据分开 | 不需要支持事务,绝大多数请求为读操作,系统崩溃后数据丢失可接受 |
| InnoDB | 支持外键,行级锁,事务,查表的总行数时需要扫表,必须有唯一索引,索引与数据在一个文件中 | 需要支持事务,读写相当,不可接受数据丢失 |
- 为什么说数据表超过2000W就会变慢?有理论依旧吗?
磁盘扇区、文件系统、InnoDB存储引擎都有各自的最小存储单元。
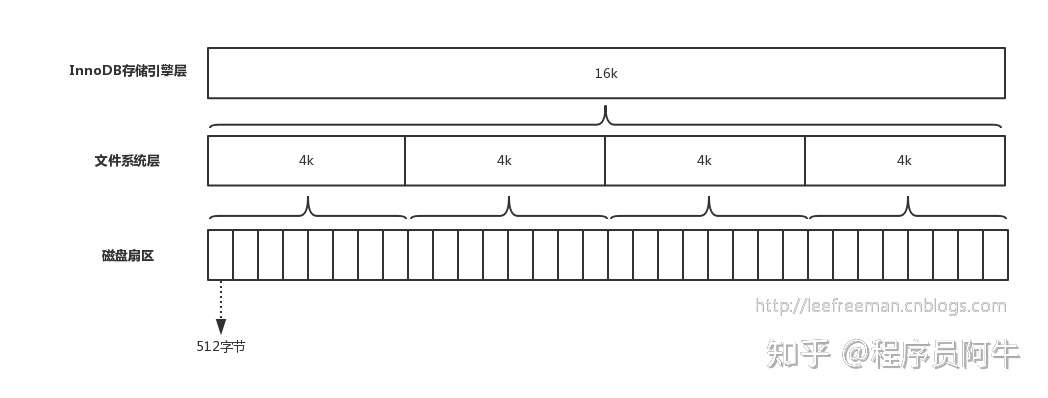
非叶子节点由索引值和指针构成:主键假设8字节;指针8字节;所以一个页最多有多少个指针呢? 16k / 16 = 1000左右。
叶子节点直接存数据,假设数据大小为1k,那么一个叶子节点存了16条记录。
所以,B+树树高为1的话,存的记录最多为16 000; 高为2的话,1000 1000 * 16 = 1600w左右。
在内存有限的情况下,多加一层,就意味着要多一次磁盘IO,性能便会急剧下降。

