什么是内存池
1.1 池化是在计算技术中经常使用的一种设计模式,其内涵在于:将程序中需要经常使用的核心资源先申请出来,放到一个池内,由程序自管理,这样可以提高资源的利用率,也可以保证本程序占有的资源数量,经常使用的池化技术包括内存池,线程池,和连接池等,其中尤以内存池和线程池使用最多。
1.2 内存池(Memory Pool)是一种动态内存分配与管理技术,通常情况下,程序员习惯直接使用new,delete,malloc,free等API申请和释放内存,这样导致的后果就是:当程序运行的时间很长的时候,由于所申请的内存块的大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。
内存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用。当程序员申请内存时,从池中取出一块动态分配,当程序员释放时,将释放的内存放回到池内,再次申请,就可以从池里取出来使用,并尽量与周边的空闲内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池。
内存池解决什么问题?
- 内存碎片问题(解决glib、操作系统层面的内存碎片问题,提供内存利用率)
- 加速了内存的分配与回收,增加了系统性能。
先说第一个,
造成堆利用率很低的一个主要原因就是内存碎片化。如果有未使用的存储器,但是这块存储器不能用来满足分配的请求,这时候就会产生内存碎片化问题。内存碎片化分为内部碎片和外部碎片。
内碎片内部碎片是指一个已分配的块比有效载荷大时发生的。(假设以前分配了10个大小的字节,现在只用了5个字节,则剩下的5个字节就会内碎片)。内部碎片的大小就是已经分配的块的大小和他们的有效载荷之差的和。因此内部碎片取决于以前请求内存的模式和分配器实现(对齐的规则)的模式。

外碎片假设系统依次分配了16byte、8byte、16byte、4byte,还剩余8byte未分配。这时要分配一个24byte的空间,操作系统回收了一个上面的两个16byte,总的剩余空间有40byte,但是却不能分配出一个连续24byte的空间,这就是外碎片问题。
每一个场景都通用的解决方案 VS 为某一个场景的定制方案
内存池设计
总体思路:
一次性向底层内存系统(依次为glibc、操作系统)申请一块大的内存慢慢使用,避免了频繁的向内存请求内存操作,提高内存分配的效率;由于向底层内存系统申请的内存块都是比较大的,所以能够降低(下一级别内存系统的)外碎片问题。
值得一提是的:内碎片问题无法避免,只能尽可能的降低。甚至,本层内存池需要通过额外的内存来管理内存,从宏观上讲(对于底层内存分配系统来讲),这是对内存的一种浪费,也可以称之为一种内部碎片。
例如,我每次只需要存储8个字节的数据,一共存储了1000次;显然这种的有效数据是8k; 但是实际上我管理着8k的数据,却使用了底层16k的内存,内存使用率只有50%。
所以,衡量一个内存池系统很重要的一方面就是:他的内存使用效率,他多大程度上降低了内存内碎片的产生。
- 内存池只能分配特定对象(数据结构)
- 充分考虑释考虑内存对象的生命周期(例如apache webserver)
- 考虑内存地址的对齐
- 考虑线程局部存储来避免不必要的锁冲突
- 除了考虑从大块内存上高效地将小内存划分出去,还要注意内存碎片问题。
- 当回收内存时要注意是否需要将相邻的空闲内存块进行合并管理。
当内存池的空闲内存到达一定的阈值时,要合理地返还系统。 - 在多核处理器能够 scale
内存池的演变
最简单的内存分配器
做一个链表指向空闲内存,分配就是取出一块来,改写链表,返回,释放就是放回到链表里面,并做好归并。
注意做好标记和保护,避免二次释放,还可以花点力气在如何查找最适合大小的内存快的搜索上,减少内存碎片,有空你还可以把链表换成伙伴算法。
优点: 实现简单
缺点: 分配时搜索合适的内存块效率低,释放回归内存后归并消耗大,实际中不实用。
定长内存分配器
定长内存分配器即实现一个 FreeList,每个 FreeList 用于分配固定大小的内存块,比如用于分配 32字节对象的固定内存分配器,之类的。每个固定内存分配器里面有两个链表,OpenList 用于存储未分配的空闲对象,CloseList用于存储已分配的内存对象,那么所谓的分配就是从 OpenList 中取出一个对象放到 CloseList 里并且返回给用户,释放又是从 CloseList 移回到 OpenList。分配时如果不够,那么就需要增长 OpenList:申请一个大一点的内存块,切割成比如 64 个相同大小的对象添加到 OpenList中。这个固定内存分配器回收的时候,统一把先前向系统申请的内存块全部还给系统。
优点: 简单粗暴,分配和释放的效率高,解决实际中特定场景下的问题有效。
缺点: 功能单一,只能解决定长的内存需求,另外占着内存没有释放。

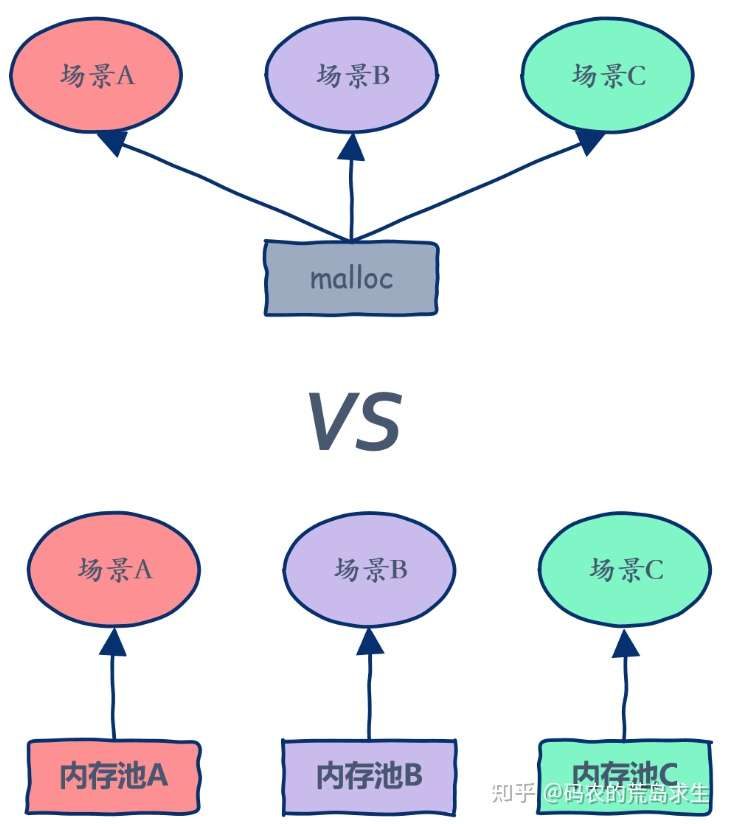
哈希映射的FreeList
池在定长分配器的基础上,按照不同对象大小(8,16,32,64,128,256,512,1k…64K),构造十多个固定内存分配器,分配内存时根据要申请内存大小进行对齐然后查H表,决定到底由哪个分配器负责,分配后要在内存头部的 header 处写上 cookie,表示由该块内存哪一个分配器分配的,这样释放时候你才能正确归还。如果大于64K,则直接用系统的 malloc作为分配,如此以浪费内存为代价你得到了一个分配时间近似O(1)的内存分配器。这种内存池的缺点是假设某个 FreeList 如果高峰期占用了大量内存即使后面不用,也无法支援到其他内存不够的 FreeList,达不到分配均衡的效果。
优点:这个本质是定长内存池的改进,分配和释放的效率高。可以解决一定长度内的问题。
缺点:存在内碎片的问题,且将一块大内存切小以后,申请大内存无法使用。多线程并发场景下,锁竞争激烈,效率降低。
范例:sgi stl 六大组件中的空间配置器就是这种设计实现的。
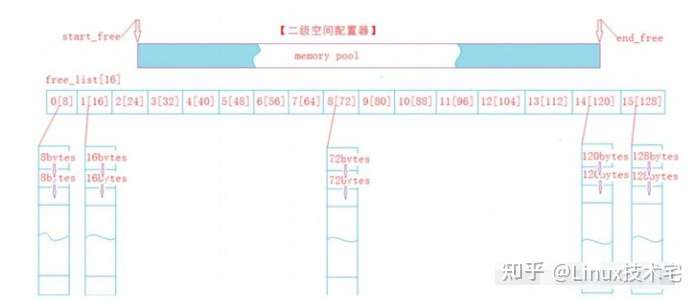
并发内存池
第一层是Thread Cache,线程缓存是每个线程独有的,在这里设计的是用于小于64k的内存分配,线程在这里申请不需要加锁,每一个线程都有自己独立的cache,这也就是这个项目并发高效的地方。
第二层是Central Cache,在这里是所有线程共享的,它起着承上启下的作用,Thread Cache是按需要从Central Cache中获取对象,它就要起着平衡多个线程按需调度的作用,既可以将内存对象分配给Thread Cache来的每个线程,又可以将线程归还回来的内存进行管理。Central Cache是存在竞争的,所以在这里取内存对象的时候是需要加锁的,但是锁的力度可以控制得很小。
第三层是Page Cache,存储的是以页为单位存储及分配的,Central Cache没有内存对象(Span)时,从Page cache分配出一定数量的Page,并切割成定长大小的小块内存,分配给Central Cache。Page Cache会回收Central Cache满足条件的Span(使用计数为0)对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
一些常见的内存分配策略
如何分配定长记录
最大化内存使用率,最小化分配时间
- bitmap来管理定长记录
内存使用率:bitmap需要额外内存,有一定浪费
时间分配效率:$O(1)$
- FreeList来管理定长记录
内存使用率:100%
时间分配效率:$O(1)$
如何分配变长记录
变长记录进行“取整”操作,带来了内存碎片问题,我们只能减少,而无可避免。
为了减少内部碎片,分配规则按照 8, 16, 32, 48, 64, 80,并非2的幂次级
FreeList来管理“取整”之后的定长记录
内存使用率:有一定的内存碎片
时间分配效率:$O(1)$
以上分配方式都是基于page,当分配小于page的对象时会使用。
大的对象如何分配
首先,每一个线程有一块ThreadCache来管理从CentralCache分配的内存
由于ThreadLocal,所以从ThreadCache分配内存不需要加锁。
CentralCache通过page以及span来管理内存,当需要分配内存时,会通过spinlock来加锁保护。
span关键属性:是否空闲、startPageId, pageNum
page关键属性:是否空闲
通过Buddy系统来管理所有空闲的page, 而分配出去的Page通过RadixTree来管理起来。
通过RadixTree管理有两个好处:
- 节省内存,按需分配
- 查询性能也还不错,等价于树高度

