熔断简单说明
在分布式系统中,一次完整的请求可能需要经过多个服务模块的调用,请求在多个服务中传递,服务对服务的调用会产生新的请求,这些请求共同组成了这次请求的调用链。当调用链中的某个环节,特别是下游服务不可用时,将会导致上游服务调用方不可用,最终将这种不可用的影响扩大到整个系统,导致整个分布式的不可用,引起服务雪崩现象。
为了避免这种情况,在下游服务不可用时,保护上游服务的可用性显得极其重要。对此我们可以通过熔断的方式,通过及时熔断服务调用方和服务提供方的调用链,保护服务调用方资源,防止服务雪崩现象的出现。
使用服务熔断,能够有效地保护服务调用方的稳定性,它能够避免服务调用者频繁调用可能失败的服务提供者,防止服务调用者浪费cpu、线程和IO资源等,提高服务整体的可用性。
所以,熔断设计的目的是在服务提供方不可用时保护服务调用方的资源,减少服务调用中无用的远程调用。
常见熔断策略
google SRE 自适应熔断
基于失败率
drop_ratio = $max(0, (requests - K * accepts) / (requests + 1))$
算法参数:
- requests:窗口时间内的请求总数
- accepts:正常请求数量
- K:敏感度,K 越小越容易丢请求,一般推荐 1.5-2 之间
算法解释:
- 正常情况下 requests=accepts,所以概率是 0。
- 随着正常请求数量减少,当达到 requests == K* accepts 继续请求时,概率 P 会逐渐比 0 大开始按照概率逐渐丢弃一些请求,如果故障严重则丢包会越来越多,假如窗口时间内 accepts==0 则完全熔断。
- 当应用逐渐恢复正常时,accepts、requests 同时都在增加,但是 K*accepts 会比 requests 增加的更快,所以概率很快就会归 0,关闭熔断。
brpc熔断策略
在开启了熔断之后,CircuitBreaker会记录每一个请求的处理结果,并维护一个累计出错时长,记为acc_error_cost,当acc_error_cost > max_error_cost时,熔断该节点。
两个小技巧:
- 利用EMA(移动平均值)策略计算接口的平均响应时间
- 利用双时间窗口统计来平衡短期抖动与长期错误率过高;
具体见:
CircuitBreaker
netflix 断路器
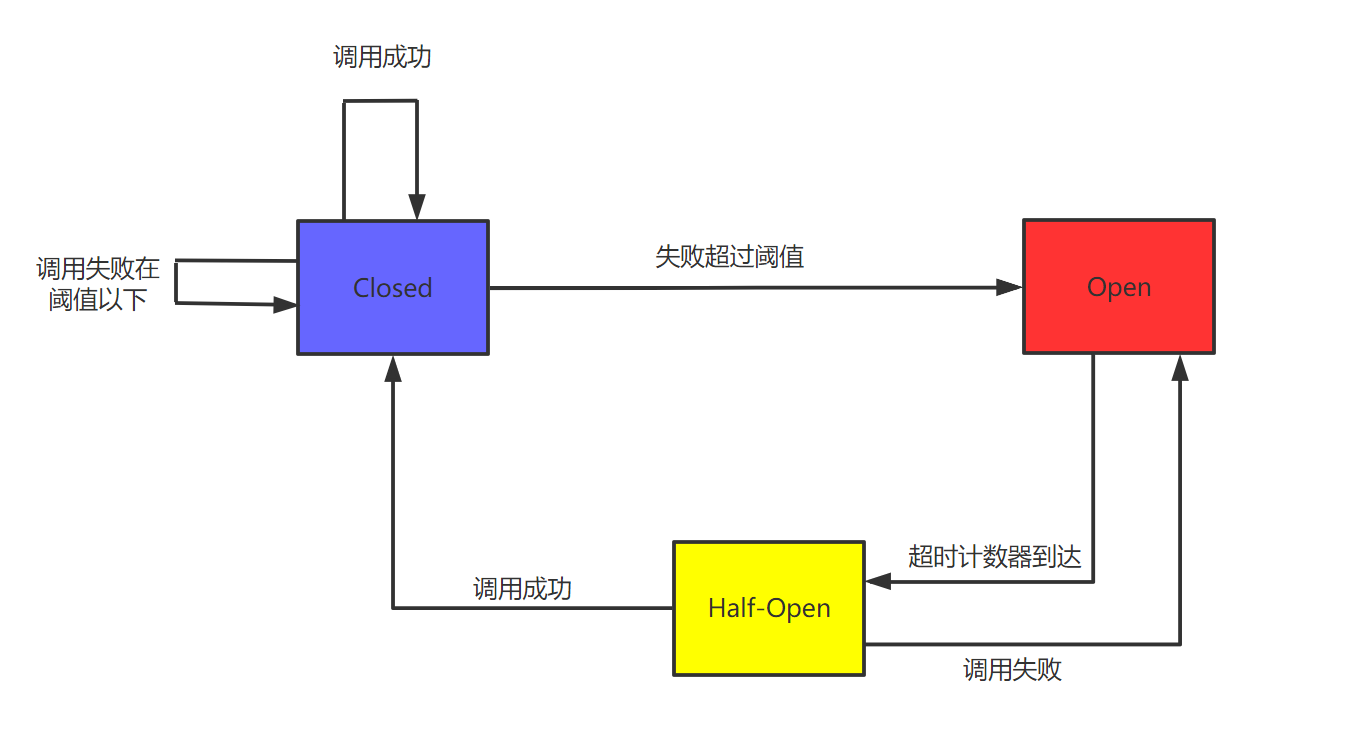
三种断路器状态:关闭、打开、半开
最近一段时间内的错误率 = 错误数 / 总数
最近一段时间内的错误数与总数,通过滑动窗口来实现,而滑动窗口又通过环形队列来实现。
错误率超过多少,则进入打开状态,持续一段时间。
持续一段时间后,进入半开状态,允许定量的请求通过,如果成功的比例足够大,则进入关闭状态,否则重新加入打开状态。

