高速缓存
思想:索引思想、折中思想
- 直接映射ByHash
主存中的一个块只能映射到Cache的某一特定块中去。例如,主存的第0块、第16块、……、第2032块,只能映射到Cache的第0块;而主存的第1块、第17块、……、第2033块,只能映射到Cache的第1块……
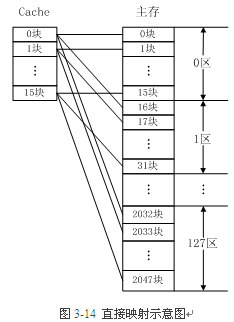
直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。
但是这种方式不够灵活,Cache的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使Cache效率下降,
因此只适合大容量Cache采用。
例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低
- 全相连映射ByAll
图3-15 是全相联映射的Cache组织,主存中任何一块都可以映射到Cache中的任何一块位置上
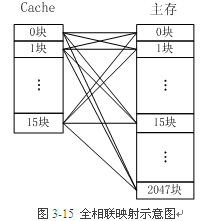
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。
但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
- 组相连映射ByGroup
组间直接相连,组内全相连
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图3-16所示。主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成u组,每组v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。例如,主存分为256组,每组8块,Cache分为8组,每组2块。
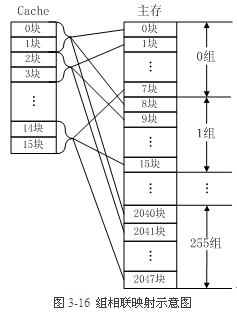
主存中的各块与Cache的组号之间有固定的映射关系,但可自由映射到对应Cache组中的任何一块。例如,主存中的第0块、第8块……均映射于Cache的第0组,但可映射到Cache第0组中的第0块或第1块;主存的第1块、第9块……均映射于Cache的第1组,但可映射到Cache第1组中的第2块或第3块。
常采用的组相联结构Cache,每组内有2、4、8、16块,称为2路、4路、8路、16路组相联Cache。
组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
具体参考:https://blog.csdn.net/weixin_34319111/article/details/92562285
一致性协议
MESI 缓存一致性协议
Modified、Exclusive、Shared、Invalid

