统计一个数字在排序数组中出现的次数。
例如输入排序数组[1, 2, 3, 3, 3, 3, 4, 5]和数字3,由于3在这个数组中出现了4次,因此输出4。
样例
输入:[1, 2, 3, 3, 3, 3, 4, 5] , 3
输出:4
1 | class Solution { |
统计一个数字在排序数组中出现的次数。
例如输入排序数组[1, 2, 3, 3, 3, 3, 4, 5]和数字3,由于3在这个数组中出现了4次,因此输出4。
样例
输入:[1, 2, 3, 3, 3, 3, 4, 5] , 3
输出:4
1 | class Solution { |
假设一个单调递增的数组里的每个元素都是整数并且是唯一的。
请编程实现一个函数找出数组中任意一个数值等于其下标的元素。
例如,在数组[-3, -1, 1, 3, 5]中,数字3和它的下标相等。
样例
输入:[-3, -1, 1, 3, 5]
输出:3
注意:如果不存在,则返回-1。
1 | class Solution { |
给出一个二叉树,输入两个树节点,求它们的最低公共祖先。
一个树节点的祖先节点包括它本身。
注意:
输入的二叉树不为空;
输入的两个节点一定不为空,且是二叉树中的节点;
样例
二叉树[8, 12, 2, null, null, 6, 4, null, null, null, null]如下图所示:
8
/ \
12 2
/ \
6 4
如果输入的树节点为2和12,则输出的最低公共祖先为树节点8。
如果输入的树节点为2和6,则输出的最低公共祖先为树节点2。
实现考虑容易想到的实现思路:
第一步,找到从root到节点A的路径,计作pa;时间复杂度$O(n)$,空间复杂度$O(n)$
第二步,找到从root到节点B的路径,计作pb;时间复杂度$O(n)$,空间复杂度$O(n)$
第三步,同时遍历pa、pb,找到最后一个相同的元素,便是A、B的最低公共祖先。时间复杂度$O(n)$
综上,总的时间复杂度为$O(3n)$,空间复杂度$O(2n)$
拿到一个二叉树遍历的题目,
(1)我们首先要思考的是:要解决这个问题,哪种遍历方式最合适?
前序遍历、后序遍历、中序遍历还是层次遍历?
(2)其次,我们做出一个假设:假设我已经调用了dfs(child),并解决了这个子问题
(3)最后,基于上面的假设去思考如何解决整个问题。
针对上面的第一个问题,我们想要从下往上遍历整棵树,所以我们需要后序遍历。
同时我们做出假设,dfs(child,p,q)会返回p,q在child子树中的最低公共祖先。那么我们的代码大概会长这样:
1 | TreeNod* dfs(TreeNode* root, TreeNode* p, TreeNode* q) { |
如果在left中找到了p/q, 并且在right中也找到了p/q, 那么显然root就是最低公共祖先。
如果left中p/q, 而right没有找到,显然遍历left得到的返回值就是最低公公祖先。
另外需要注意,此处你有一个假设:p\q一定在tree中能够找到;如果该假设被打破的话,这段代码会出问题。
1 | TreeNod* dfs(TreeNode* root, TreeNode* p, TreeNode* q) { |
traceroute
ICMP ttl递减
给目标主机的不可达端口(30000+)发送UDP数据包,并且设置TTL
他从源主机到目的主机发送一连串的IP数据报p1-pn,并且数据报是无法交付的udp数据报。第一个数据报的TTL设置为1,这样当这个数据报转发到第一个路由器的时候,路由器收到后TTL减1,减完1之后发现TTL变为0,路由器会向源主机发送一个超时差错报告报文。
然后是第二个,第二个数据报的TTL设置为2,这样转发到第二个路由器的时候,TTL变为0,并会向源主机在发送一个超时差错报告报文,依次进行此操作。直到第n个数据报pn到达目的主机,但是由于数据报无法交付,因此目的主机会向源主机发送终点不可达差错报告报文。
通过这种方式,源主机就可以通过发送过来的超时差错报告报文和终点不可达差错报告报文来的得到经过的路由器以及往返时间等信息,达到路由跟踪的目的。

正常一个fd会有等待队列,表示有哪一些进程在等待fd可用;
当一个进程在等待一个fd时,内核会把进程结构体从运行队列摘除,放在fd的等待队列上【这样子内核就不会调度到该进程了】
当某个端口有数据可读时,内核会跟进端口查索引表,找到对应的fd
对于select,会频繁的将进程挂在所有FD的等待队列上,然后在select返回的时候,再重新将进程从等待队列中移除,放回到运行队列上。
当进程被唤醒的时候,用户程序也需要遍历fd array,去GET哪些FD可读。
性能极其差!
eventpoll作为一个中间结构,替代进程,挂在对应的等待队列
而调用epoll_wait的进程当被阻塞的时候是挂在在eventpoll的等待队列上。

select低效的另一个原因在于程序不知道哪些socket收到数据,只能一个一个的遍历。如果内核维护一个“就绪列表”,引用收到的数据的socket,就能避免遍历。

使用场景:
epoll 在应对大量网络连接时,只有活跃连接很少的情况下才能表现的性能优异。换句话说,epoll 在处理大量非活跃的连接时性能才会表现的优异。如果15000个 socket 都是活跃的,epoll 和 select 其实差不了太多。
epoll 的 edge-trigger 和 level-trigger 模式处理逻辑差异极小,性能测试结果表明常规应用场景 中二者性能差异可以忽略。
? 使用 edge-trigger 的 user app 比使用 level-trigger 的逻辑复杂,出错概率更高。
? edge-trigger 和 level-trigger 的性能差异主要在于 epoll_wait 系统调用的处理速度,是否是 user app 的性能瓶颈需要视应用场景而定,不可一概而论。
但从 kernel 代码来看,edge-trigger/level-trigger 模式的处理逻辑几乎完全相同,差别仅在于 level-trigger 模式在 event 发生时不会将其从 ready list 中移除,略为增大了 event 处理过程中 kernel space 中记录数据的大小。
然而,edge-trigger 模式一定要配合 user app 中的 ready list 结构,以便收集已出现 event 的 fd,再通过 round-robin 方式挨个处理,以此避免通信数据量很大时出现忙于处理热点 fd 而导致非热点 fd 饿死的现象。统观 kernel 和 user space,由于 user app 中 ready list 的实现千奇百怪,不一定都经过仔细的推敲优化,因此 edge-trigger 的总内存开销往往还大于 level-trigger 的开销。
一般号称 edge-trigger 模式的优势在于能够减少 epoll 相关系统调用,这话不假,但 user app 里可不是只有 epoll 相关系统调用吧?为了绕过饿死问题,edge-trigger 模式的 user app 要自行进行 read/write 循环处理,这其中增加的系统调用和减少的 epoll 系统调用加起来,有谁能说一定就能明显地快起来呢?
当然操作系统开发人员也会意识到这些缺陷,并且在设计poll接口时解决了大部分问题,因此你会问,还有任何理由使用select吗?为什么不直接淘汰它了?其实还有两个理由使用它:
1.第一个原因是可移植性。select已经存在很长时间了,你可以确定每个支持网络和非阻塞套接字的平台都会支持select,而它可能还不支持poll。另一种选择是你仍然使用poll然后在那些没有poll的平台上使用select来模拟它。
2.第二个原因是select的超时时间理论上可以精确到微秒级别。而poll和epoll的精度只有毫秒级。这对于桌面或者服务器系统来说没有任何区别,因为它们不会运行在纳秒精度的时钟上,但是在某些与硬件交互的实时嵌入式平台,降低控制棒关闭核反应堆.可能是需要的。(这就可以作为一个更加精确的sleep()来用)
什么时候应该选择使用Poll:
跨平台
同一时刻你的应用程序监听的套接字少于1000(这种情况下使用epoll不会得到任何益处)。
您的应用程序需要一次监视超过1000个套接字,但连接非常短暂(这是一个接近的情况,但很可能在这种情况下,您不太可能看到使用epoll的任何好处,因为epoll 的加速将这些新描述符添加到集合中会浪费等待 - 见下文
您的应用程序的设计方式不是在另一个线程正在等待它们更改事件(即您没有使用kqueue或IO完成端口移植应用程序)。
EPoll的缺点:
1.改变监听事件的类型(例如从读事件改为写事件)需要调用epoll_ctl系统调用,而这在poll中只需要在用户空间简单的设置一下对应的掩码。如果需要改变5000个套接字的监听事件类型就需要5000次系统调用和上下文切换(直到2014年epoll_ctl函数仍然不能批量操作,每个描述符只能单独操作),这在poll中只需要循环一次pollfd结构体。
2.每一个被accept()的套接字都需要添加到集合中,在epoll中必须使用epoll_ctl来添加–这就意味着每一个新的连接都需要两次系统调用,而在poll中只需要一次。如果你的服务有非常多的短连接它们都接受或者发送少量数据,epoll所花费的时间可能比poll更长。(解释了上文)
3.epoll是Linux上独有的,虽然其他平台上也有类似的机制但是他们的区别非常大,例如边沿触发这种模式是非常独特的(FreeBSD的kqueue对它的支持非常粗糙)。
什么情况下使用Epoll:
1.你的程序通过多个线程来处理大量的网络连接。如果你的程序只是单线程的那么将会失去epoll的很多优点。并且很有可能不会比poll更好。
2.你需要监听的套接字数量非常大(至少1000);如果监听的套接字数量很少则使用epoll不会有任何性能上的优势甚至可能还不如poll。
3.你的网络连接相对来说都是长连接;就像上面提到的epoll处理短连接的性能还不如poll因为epoll需要额外的系统调用来添加描述符到集合中。
4.你的应用程序依赖于Linux上的其他特性
pid1 = fork()
pid2 = fork()
printf(“pid1:%d, pid2:%d”, pid2, pid2);
一共创建了四个进程
信号是一种异步通信机制,它是在软件层面上对中断机制的一种模拟,
阻塞信号
信号有几种状态,首先是信号的产生 (Genertion),而实际执行信号处理动作时,状态为递达 (Delivery),信号在产生到递达中的状态被称为未决 (Pending)
进程可以选择阻塞 (Blocking)某些信号,被阻塞的信号在产生后将保持在未决状态,直到进程解除对该信号的阻塞,才执行递达的动作
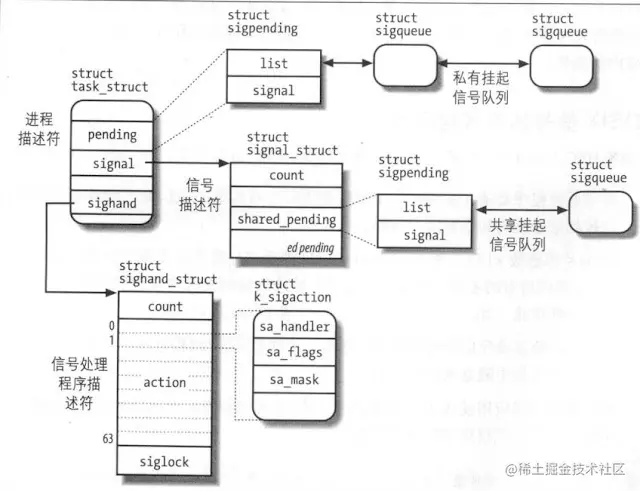
1.4 信号的处理时机
信号是在什么时候被处理的呢?是在被投递的时候处理的吗,不是的。信号是在线程将要返回用户空间之前进行处理的。线程返回用户空间有两种情况,一是从系统调用返回,二是从中断返回。返回之前,线程会检查队列里有没有信号要处理,有的话就处理。
1.5 信号与多线程
信号的发送既可以发送给进程,也可以发送给线程,但是同步信号(也就是和当前线程执行相关而产生的信号)应当发送给当前线程。进程发送信号可以选择不同的接口函数,有的接口是发给进程的,有的接口是发给线程的。线程信号队列中的信号只能由线程自己处理,进程信号队列中的信号由进程中的线程处理,具体是由哪个线程处理是不确定的。
信号掩码(mask)的设置是线程私有的,每个线程都可以设置不同的信号掩码。
信号处理方式的设置是进程全局的,后面线程设置的方式会覆盖前面线程的设置。
信号处理的效果是进程全局的。
消息事务是指一系列的生产、消费操作可以要么都完成,要么都失败,类似数据库的事务。这个特性在0.10.2的版本是不支持的,从0.11版本开始才支持。华为云DMS率先提供Kafka 1.1.0的专享版服务,支持消息事务特性。
Basic-Paxos解决的问题:在一个分布式系统中,如何就一个提案达成一致。
https://blog.csdn.net/yangmengjiao_/article/details/120191314
raft将共识问题分解成两个相对独立的问题,leader election,log replication。