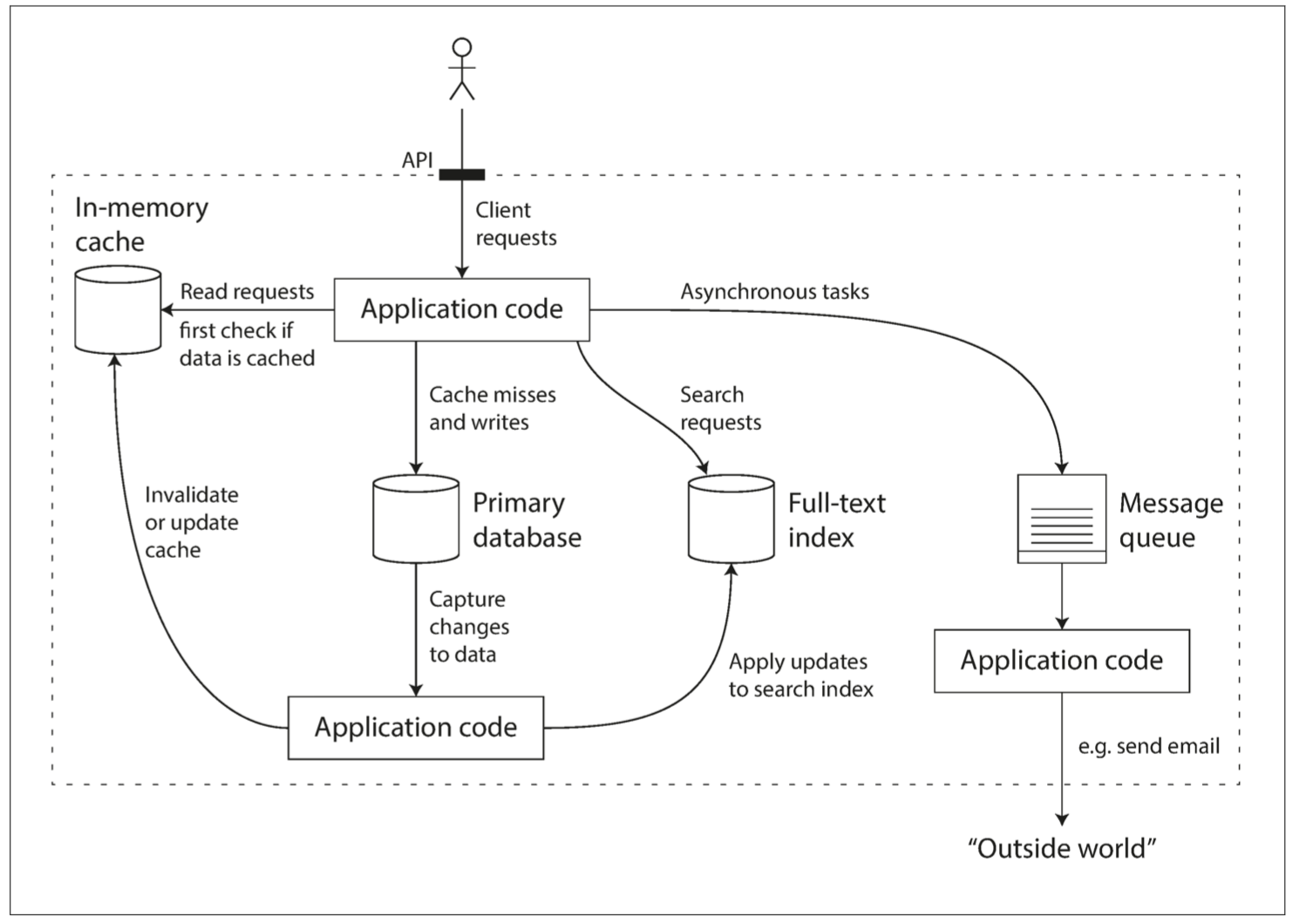
为什么会有分布式
两点:算得慢(算力不足),存不下(数据分散)。
无论是线程、进程,还是协程,本质上,目的都是为了计算的并行化,解决的是算的慢的问题。
因为一个CPU算不过来,而单机扩容CPU数量成本极高(有空间这个刚性限制),所以需要水平扩容,多搞几台机器。
计算的分布式化:基于分治思想,出现了分布式框架。
MapReduce: 分布式计算的总体思想。
分布式计算框架更多尝试对资源的调度做优化。ResourceManager, yarn, k8s;
(多租户,隔离,软隔离,租借,抢占等)
高并发系统的三个目标与挑战
高并发是一个系统的挑战
如何衡量一个系统的并发有多高呢? 同时在线人数
高性能、高可用、可扩展是一个牛B系统目标
三者的关系
为了保证高可用,需要冗余更多的相同功能机器(replication),要求系统可扩展;
为了保证高性能,必须需要更多的相同功能的机器(存储的replication、应用的无状态)或者服务于不同对象的机器(shard),也要求可扩展;
一份完整的数据,分为多个shard的过程需要可扩展;
一份数据冗余了多份,前端对下游访问时用到的负载均衡策略需要可扩展。
如何衡量一个吞吐量有多大呢?
系统的QPS,吞吐量 = 并发进程数 / 响应时间
如何衡量一个系统的性能有多高呢?
一旦系统的负载被描述好,就可以研究当负载增加会发生什么。我们可以从两种角度来看:
- 增加负载参数并保持系统资源(CPU、内存、网络带宽等)不变时,系统性能将受到什么影响?(接口响应时间,分位耗时)
- 增加负载参数并希望保持性能不变时,需要增加多少系统资源?
如何衡量一个系统的可用性有多高呢?
平均故障间隔,平均故障恢复时间

如何衡量一个系统的可扩展能力?
考察一个问题:能够通过增加进程来应对更高的并发? 如果一直加机器,我一直能线性的提高系统的处理能力吗?
如何应对系统的挑战
架构通用原则:“4 要 1 不要”
(1) 数据要尽量少
- 用户请求的数据能少就少
- 系统依赖的数据能少就少
(2) 请求数要尽量少
例如,静态文件合并
(3)路径要尽量短
将强依赖的服务进行单机部署
(4)依赖要尽量少
系统服务分级,高等级服务尽量少依赖低等级服务
(5)不要有单点
服务无状态,可扩展;存储层做副本备份